


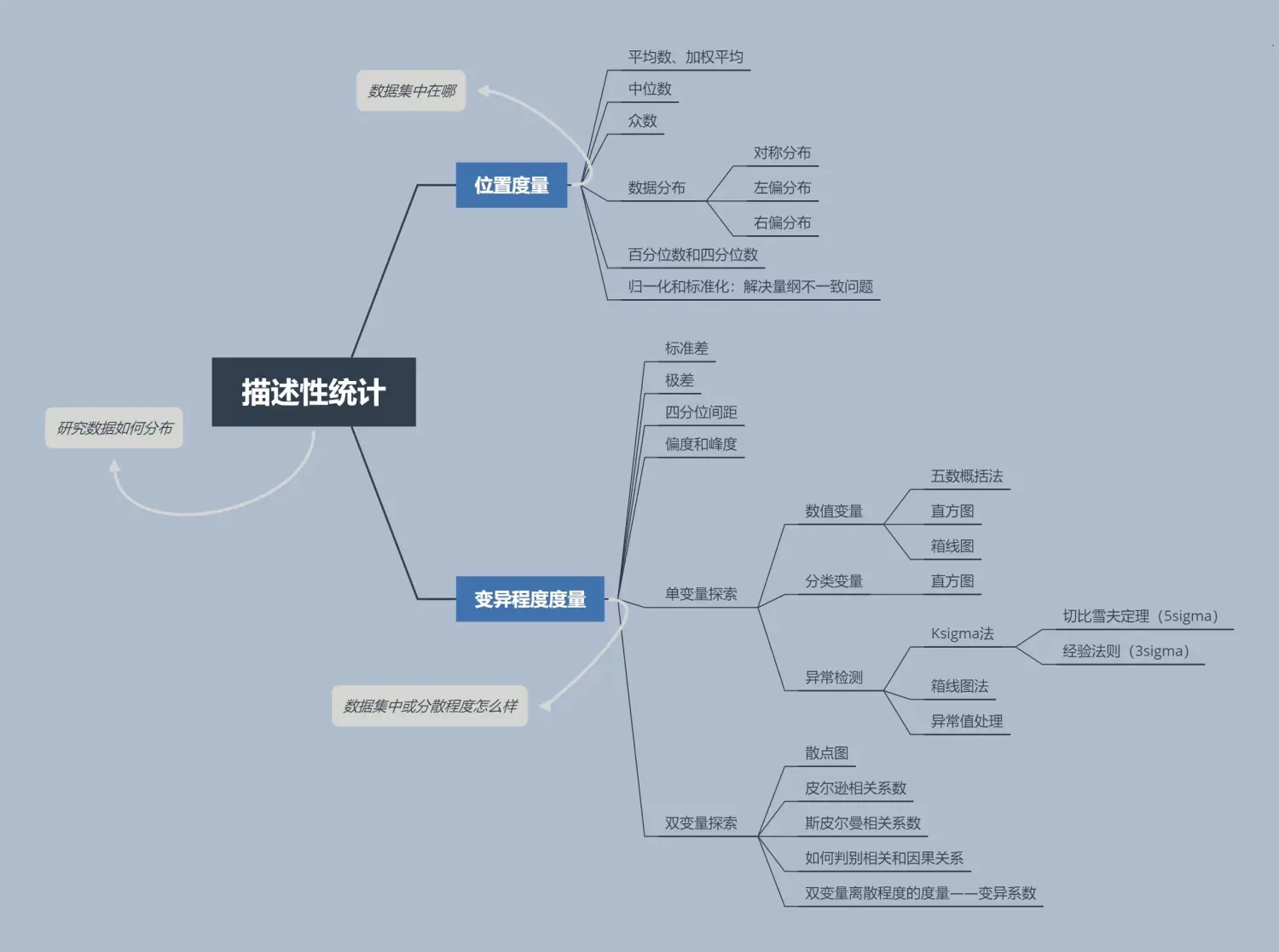
统计学是数据分析的基石,也是数据分析师的根本。学了统计学,你会发现很多时候的分析并不靠谱。比如很多人都喜欢用平均数去分析一个事物的结果,但是这往往是粗糙的,不准确的。如果学了统计学,那么我们就能以更多更科学的角度看待数据。用统计学作为数据分析的支撑和方向,使得分析结果更加有底气。本文主要分享描述性统计理论结合对应的python实现方式,更好的帮助大家将统计学应用到实际工作中。
什么是描述性统计
描述性统计是通过图表或数学方法,对数据资料进行整理、分析,并对数据的分布状态、数字特征和随机变量之间关系进行评估和描述的方法。
一、描述性统计——位置度量【数据集中在哪里】
1、平均值
import pandas as pd
df = pd.DataFrame([3000,4000,4500,5000,5500,6000,20000],columns=['salary'])
df.mean()

缺点:极易受异常值的影响
解决:结尾均值或者取中位数
-
结尾均值: 将数据进行从小到大排序后,按照一定比例去掉两端数据,只使用中间部分数据来取平均值。数据量大一般前后取5%,数据量少去头尾即可。
df[df['salary'].isin([df['salary'].min(),df['salary'].max()])==False].mean()

平均值的两个误区 !
①加权平均:给平台用户打分(近三个月的消费频次R,消费间隔F、消费金额M)
df_user = pd.DataFrame({'user_id':[1,2,3,4,5],'R':[3,6,7,10,7],'F':[10,5,9,2,6],'M':[5000,6500,7000,3500,100]})
df_user

这时我们要和业务沟通,可以依据业务经验给这三个维度一个权重值,注意权重总和为1
假如现在的权重值是【0.2,0.3.0.5】
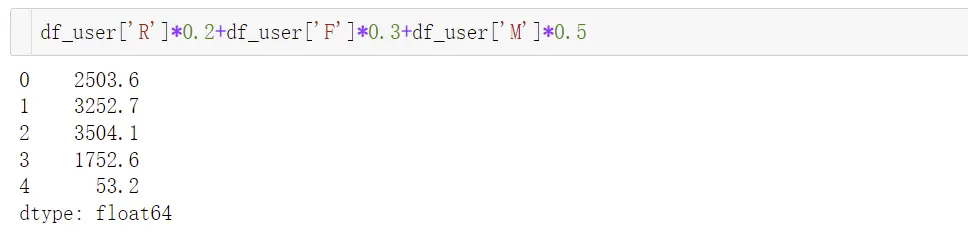
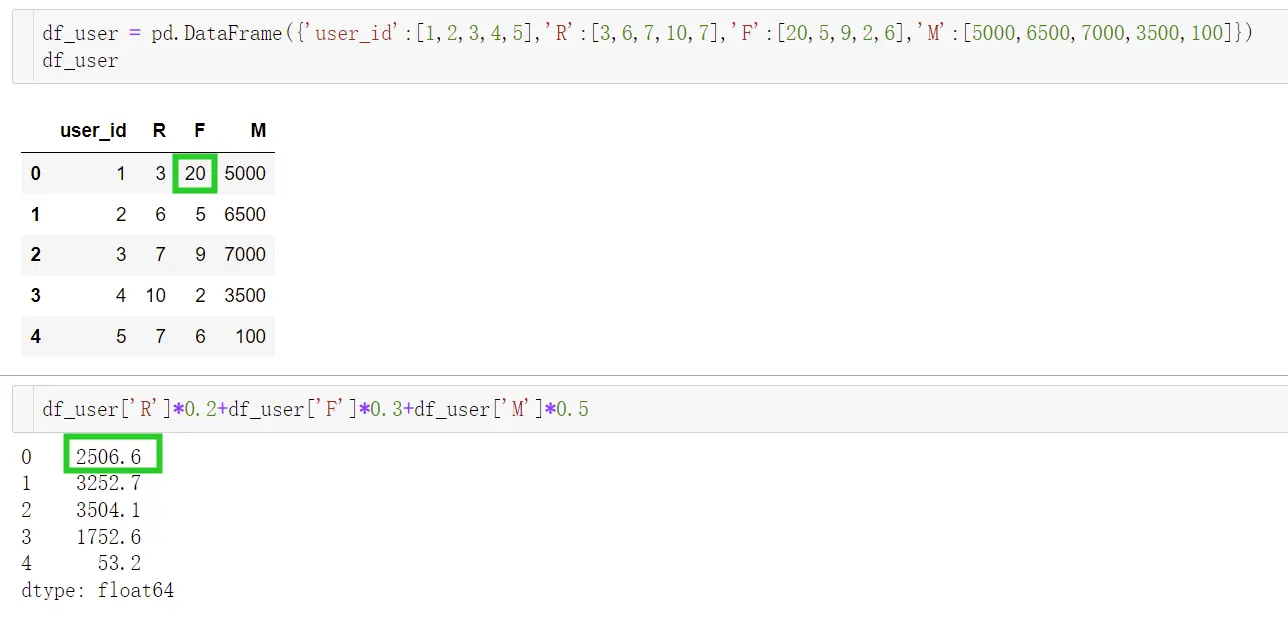
将用户ID 为 1 用户的F值提升了1倍,总的评分才上升了3,这样的结果明显不够准确,这是大家很容易忽略的一点,造成这个问题的原因是因为量纲不一致,RF和M的值相差过大。可以通过对原始数据进行标准化和归一化解决。
-
标准化(Standardization):将数据转换成均值为0,标准差为1的分布,并非一定是正态的,数值没有固定范围。
-
归一化1(Normalization):将一列数据变化到某个固定区间中,通常这个区间是【0,1】 -
归一化2(Mean Normalization):范围【-1,1】,将分子的Xmin换成Xmean即可。
使用:若对数据范围有严格要求,用归一化(存在极端最大和最小值需要做截尾处理),其余用标准化。


# 标准化
#x 代表每个值,data代表一组数据
def standardization(x,data):
value = (x - data.mean())/(data.std())
return value
# 归一化1
def normalization1(x,data):
value = (x - data.min())/(data.max() - data.min())
return value
# 归一化2
def normalization2(x,data):
value = (x - data.mean())/(data.max() - data.min())
return value
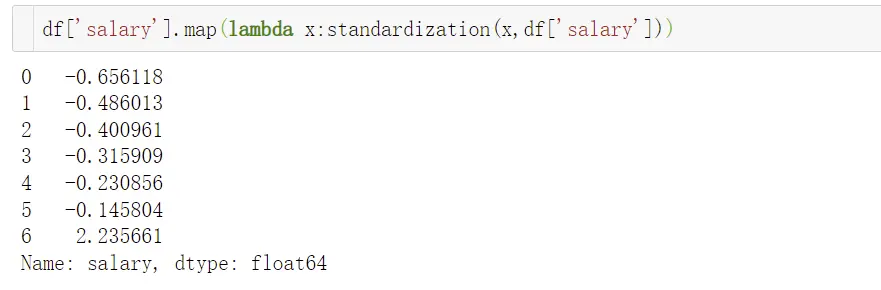
df_user['old'] = df_user['R']*0.2+df_user['F']*0.3+df_user['M']*0.5
df_user['new']=(df_user['R'].map(lambda x:standardization(x,df_user['R'])))*0.2+(df_user['F'].map(lambda x:standardization(x,df_user['F']))*0.3+
(df_user['M'].map(lambda x:standardization(x,df_user['M'])))*0.5)
df_user
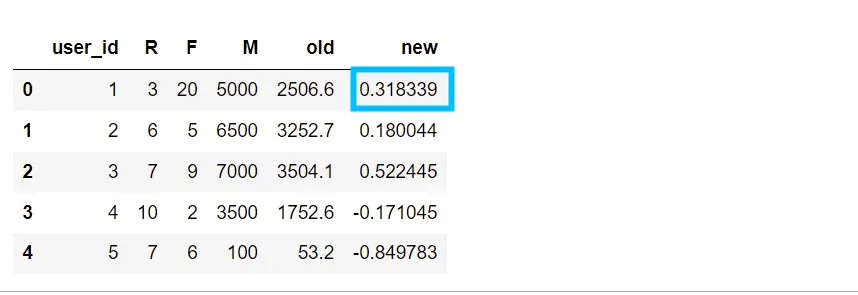
通过标准化数据会发现,ID是1 的用户排名变成了第二,虽然消费金额不高,但是消费频次是最高的,所以对应评分是高的。标准化和归一化主要的目的,是帮助我们解决量纲不一致的问题,加权平均之前要解决量纲不一致问题,而加权平均应用场景是打分,用来做精准营销和广告投放等。
②均值使用的误区
第一天,有10 个用户,共充值了50块钱,人均充值了5块钱
第二天,有15个用户,共充值了90块钱,人均充值了6块钱
第三天,有8个用户,总共充值了64块钱,人均充值了8块钱
问这三天的日平均消费金额是多少?

2、中位数
将数据从小到大排序,取中间的数(偶数:中间两个数的平均值)

中位数代表一个样本,种群和概率分布中的一个数值,将其划分为上下相等两部分,中位数和均值越接近,说明异常值较少。
3、众数
出现次数最多的数(占比例最大,适用于非数值型数据)
4、数据分布
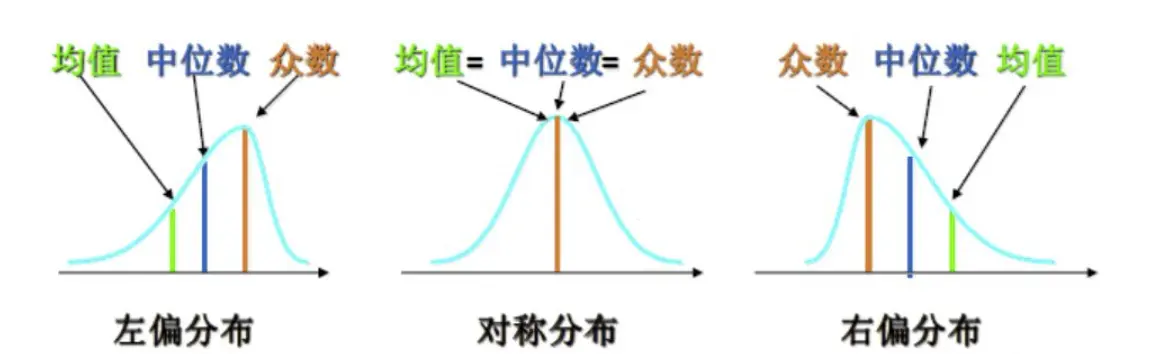
- 对称分布:平均值=中位数=众数
- 左偏分布:平均值
- 右偏分布:众数
注:左偏右偏是针对平均数来说的,不是视觉上
5、百分位数和四分位数
解决数据如何散布再从最小值到最大值的区间上的信息,第p个百分位数,表示至少有p%的观测值小于或者等于该值,且至少有(100-p)%的观测值大于或者等于该值


解释:至少有51%的观测值小于或等于5030,至少有49%的观测值大于5030
四分位数:第一四分位数Q1,第二四分位数Q2,第三四分位数 Q3
Q1 = 25%百分位数
Q2 = 50%百分位数 = 中位数
Q3 = 75%百分位数
二、描述性统计——变异程度度量【解决数据集中或分散程度怎么样】
1、标准差
标准差是一组数值自平均值分散开来的程度的一种测量概念。一个较大的标准差,代表大部分的数值和平均值差距较大;一个较小的标准差,代表这些数值和平均值接近。
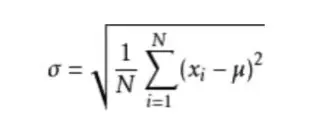

- 案例:教练想选一个发挥稳定的球员,该选谁?
df2 = pd.DataFrame({'A':[20,30,25,35,35],'B':[10,50,55,15,20],'C':[15,30,40,45,20]})
print('A的历史平均分:',df2['A'].mean())
print('B的历史平均分:',df2['B'].mean())
print('C的历史平均分:',df2['C'].mean())

print('A的标准差:',np.std(df2['A']))
print('B的标准差:',np.std(df2['B']))
print('C的标准差:',np.std(df2['C']))

结论:标准差越小,代表发挥越稳定,选A。
2、极差
极差 = 最大值 – 最小值 , 极易受到异常值的影响

3、四分位间距
- IQR = Q3 – Q1
- 作为变异程度的一种独立,能够克服异常值的影响
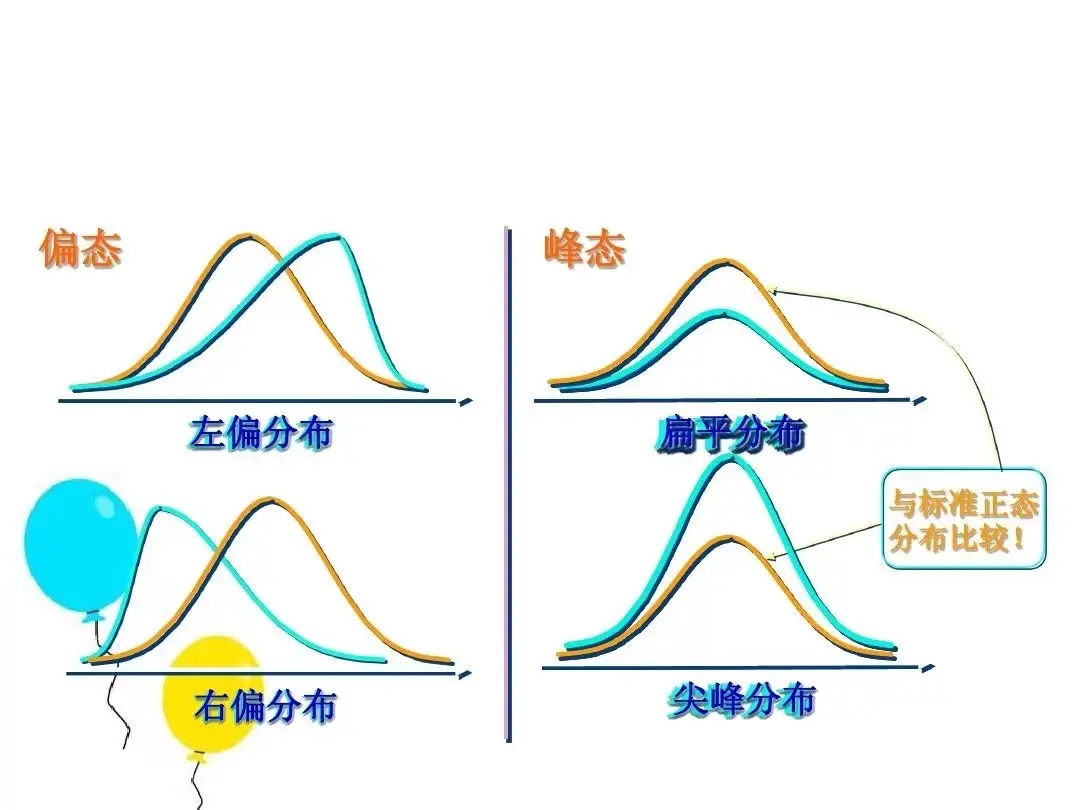
4、偏度(Skewness)
偏度是统计数据分布偏斜方向和程度的度量,是统计数据分布的非对称程度的数字特征。
- 当 SK>0时,值越大,右偏程度越高
- 当 SK
- 当 SK=0时,对称分布
5、峰度(Kurtosls)
峰度是指次数分布曲线顶峰的尖顶程度,是次数分布的又一重要特征,通常以正态
分布为标准。
- 当变量值的次数在众数周围分布的比较集中,使次数分布区曲线正态分布曲线顶峰更为”尖峭”,称为尖顶峰度。当K > 0 ,数据尖峰,两侧存在离群值。
- 当变量值的次数在众数周围分布的比较分散,使次数分布区曲线正态分布曲线顶峰更为”平缓,称为平顶峰度。当K
- 当 K=0时,趋于正态分布。
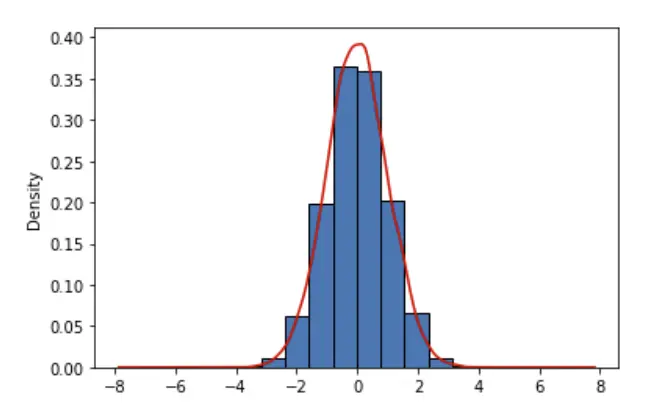
# random.randn 生成标准正态分布
d = list(np.random.randn(10000))
data = pd.Series(d)
data.plot(kind='hist',density=True,edgecolor='black')
data.plot(kind='kde',color='red')
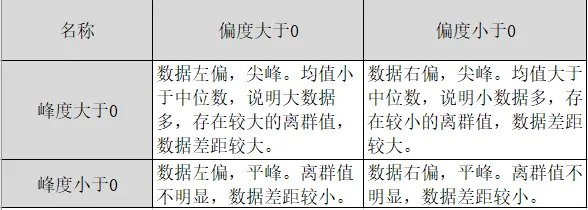
print('偏度',data.skew())
print('峰度',data.kurtosis())

结果说明:峰度和偏度接近于0,说明数据是服从正态分布的对称分布曲线。
6、单变量探索
- 数值变量:查看数据分布情况、是否有异常值和量纲问题
①五|八数概括法
最小值、第一分位数、正位数、第三四分位数、最大值

②直方图

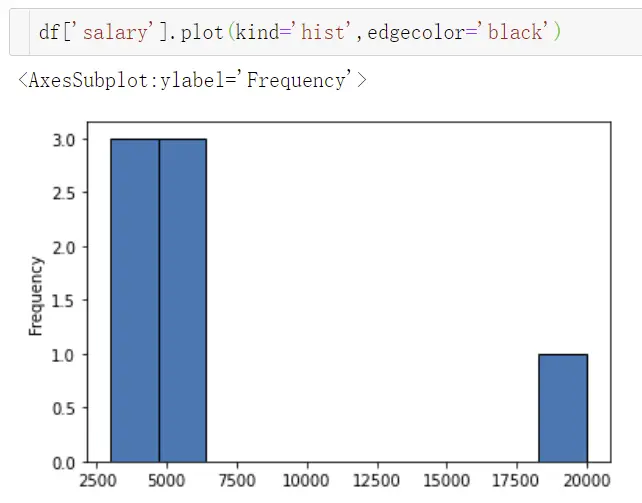
③箱线图

-
分类变量
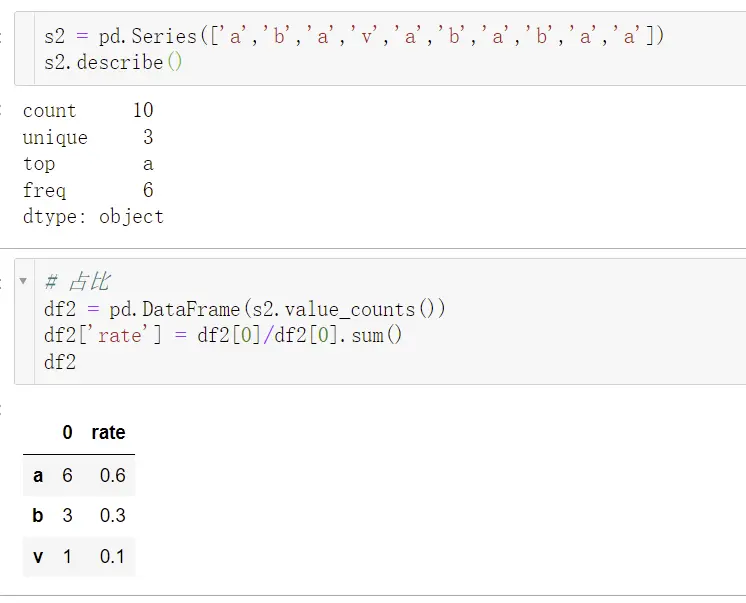
统计学:怎么做异常值检测?
异常值:有时数据集包含一个或多个数值异常大或异常小的观测值,这样的极端值称为异常值。
①Ksigma法
②箱线图法(用的多)
Ksigma法
- 5sigma:切比雪夫定理
在任意一个数据集中
所有的数据中,至少有3/4(或75%)的数据位于平均数2个标准差范围内。
[mean - 2*std,mean + 2*std]
所有的数据中,至少有8/9(或88.9%)的数据位于平均数3个标准差范围内。
所有的数据中,至少有24/25(或96%)的数据位于平均数5个标准差范围内。
- 3sigma:经验法则(用的多)
当数据集符合正态分布时
那么有68.3%的数据位于平均数1个标准差范围内。
那么有95.5%的数据位于平均数2个标准差范围内。
那么有99.7的数据位于平均数3个标准差范围内。
def Ksigma(k,data_list):
error_list = []
avg = np.mean(data_list)
std = np.std(data_list)
t_up = avg - k*std
t_down = avg + k*std
print('上限',t_up,'下限',t_down)
for i in data_list:
if (it_down):
error_list.append(i)
return error_list
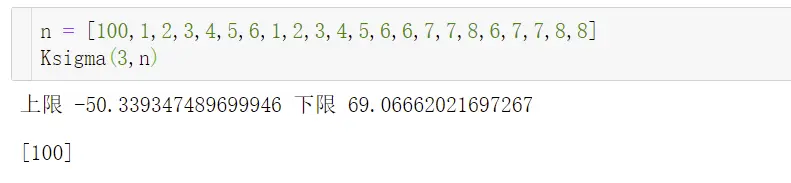
3sigma虽然是常用的,但是存在一定的缺点:①数据是服从正态分布的或者近正态分布②输出的正常区间容易受异常值影响,而导致结果不准。
如何检验是否是正态分布:峰度和偏度接近0
箱线图法
能弥补Ksigma的缺点
①计算第一分位数Q1 和 第三分位数Q3
②计算IQR = Q3 -Q1
③输出正常区间[Q1-1.5IQR,Q3+1.5IQR]
def NumOutlier(data_list):
error_list = []
iqr = np.quantile(data_list,0.75) - np.quantile(data_list,0.25)
t_up = np.quantile(data_list,0.25)-1.5*iqr
t_down = np.quantile(data_list,0.75)+1.5*iqr
print('上限',t_up,'下限',t_down)
for i in data_list:
if (it_down):
error_list.append(i)
return error_list

异常值的常用处理方法
- 删除
- 中位数替代
- 用前后两个观测值的平均值修正
7、双变量探索
①散点图
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.family'] = 'SimHei'
sca = pd.read_excel(r'C:UserscherichDesktoptest_datas.xlsx',sheet_name='时长与成绩')
ti = sca['时长']
score = sca['成绩']
plt.figure(figsize=(6,4),dpi=80)
plt.scatter(ti,score,s=100,c='#6699ff',marker='*')
plt.title('学习时长和成绩之间的关系',fontsize=20,pad=10)
plt.xlabel('时长')
plt.ylabel('成绩')
plt.show()
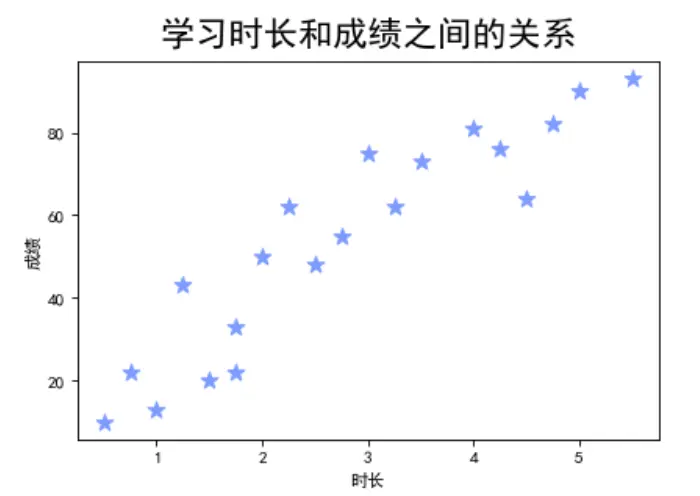
②皮尔逊相关系数
- 目的:计算两个数值型变量的线性关系,当两个变量非线性时,相关系数为0。
- 取值范围:[-1,1],正数代表正相关,负数代表负相关
- 相关系数分类:
0.8~1.0 极强正相关
0.6~0.8 强相关
0.4~0.6 中等程度相关
0.2~0.4 弱相关
0~ 0.2 极弱相关或无关 - 使用皮尔逊相关系数的前提:
两个变量之间具有线性关系
变量是数值型
异常值较少
样本数最好大于30
样本的标准差不能为0
案例:成绩和学习时长之间的关系,应如何计算?
第一步:观察是否有线性关系
第二步:看是否有异常值
第三步:看标准差是否为0
第四步:计算相关系数
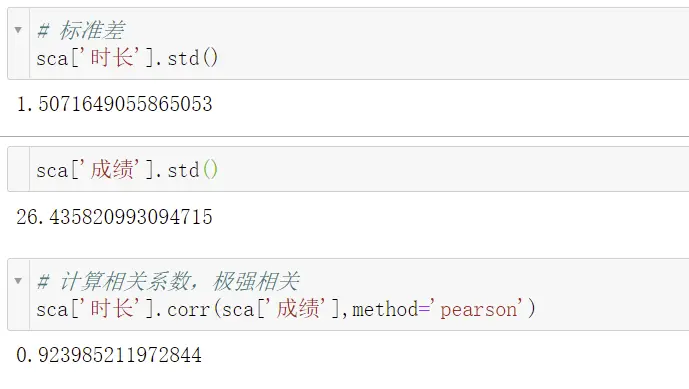
结果说明:极强相关怎么理解?最终计算出的结果是一个概率值,本案例中可以理解为影响成绩的因素 92% 是和学习时长有关。
③ 斯皮尔曼相关系数
- 它能解决皮尔逊相关系数不能解决的问题,比如皮尔逊能解决线性相关问题,斯皮尔曼能解决非线性相关问题
- 目的:根据等级资料研究两个变量间相关关系的方法,它是根据两列成对等级的各对等级数之差来进行计算的
- 取值范围:[-1,1],正数代表正相关,负数代表负相关
- 优点:处理非线性,对异常值不敏感,可用于定序型离散值变量
定序型变量:具有内在固有大小或者高低循序,一般用数字和字符来表示。如职称有高、中、低,用1,2,3表示;比如年龄段有老、中、青,用A、B、C来表示。
- 缺点:处理线性时,精确度和效率都不如皮尔逊
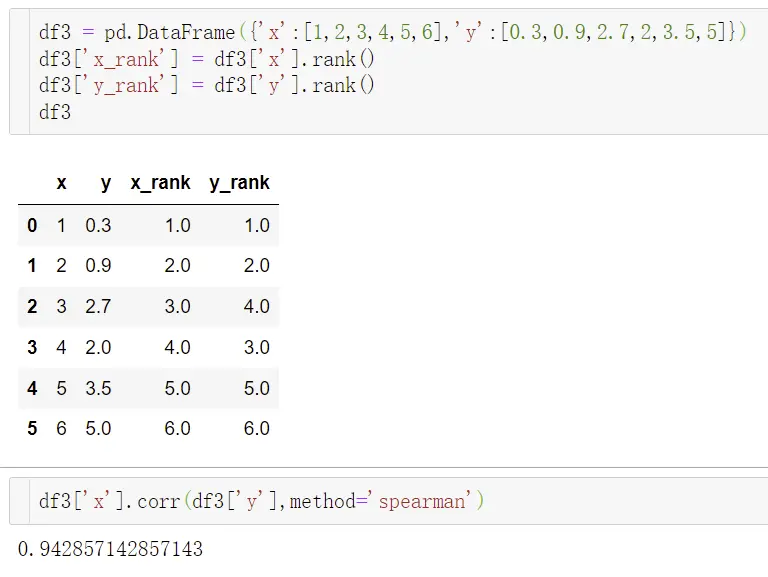
如何选择相关系数
- ①连续数据、线性关系、正态分布用皮尔逊最恰当
- ②上述任意一条件不满足,就用斯皮尔曼相关系数
- ③两个定序测量数据之间也用斯皮尔曼相关系数
如何判定相关还是因果关系?
相关:是两个或两个以上变量之间互相影响的的程度,核心是互为相关,同时存在没有先后顺序。
因果:前一个事件对后一个事件的作用和强度,核心点是有先后顺序的。
相关关系和因果关系的判断依据:因果关系是一定(粗暴理解相关系数为1),相关关系是一个概率问题。
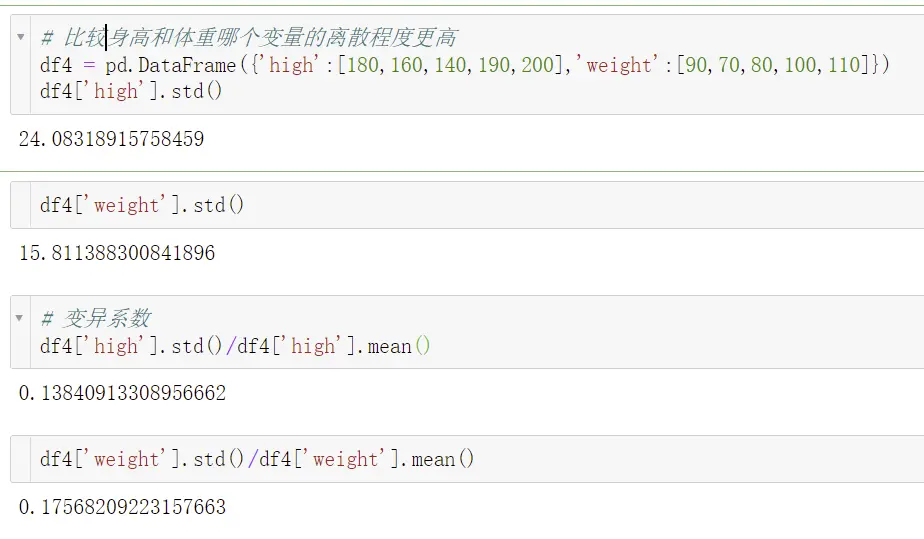
8、双变量离散程度的度量——变异系数
应用场景:当需要比较两组数据离散程度大小的时候,如果两组数据的测量尺度相差太大或者量纲不同时,使用标准差不合适,此时就应该消除测量尺度和量纲的影响,而变异系数就能做到这一点,它是原始数据标准差与原始数据平均数的比。
公式:标准差/平均数
- 缺点:当平均数接近于0的时候,微小的扰动也会对变异系数产生巨大的影响,因此造成精度不足。
以上主要介绍了集中趋势的度量、离散程度的度量、分布形态的度量。当业务人员/老板拿到一堆数据,丢到你面前,让你分析。这时你不会不知所措,也不会不知道从哪一步开始整理这些数据。你可以通过概括性的度量指标,来帮我们从更科学的角度发现数据问题,开展数据分析工作。
最后,感觉文章对你有帮助的小伙伴,记得点赞、关注噢!
【信息由网络或者个人提供,如有涉及版权请联系COOY资源网邮箱处理】




暂无评论内容